In jedem Lehrbuch zur Datenbankentwicklung erfahren Sie, wie wichtig die Indizierung von Tabellenfeldern ist. Das betrifft jene, die in Vergleichs- und Filterabfragen eingeschlossen werden sollen und außerdem die Felder, welche mehrere Tabellen über Indexfelder über Schlüssel miteinander verknüpfen. Ziel sind möglichst performante Abfragen der Datenbank. Wir untersuchen hier, wie groß der Performancezuwachs in der Praxis tatsächlich ist.
Beispieldatenbank
Die Beispiele dieses Artikels finden Sie in der Datenbank 1702_Indizes.zip.
Wozu Indizierung
In einer relationalen Datenbank gilt die Indizierung von mindestens den Verknüpfungsfeldern der Tabellen als das A und O. Sehen Sie sich dazu etwa das Datenmodell von Kunden und deren Bestellungen in Bild 1 an.
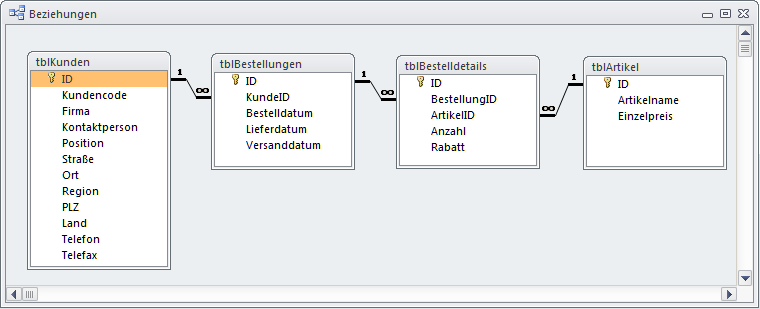
Bild 1: Die vier Tabellen der Kundendatenbank sind alle miteinander über Schlüsselfelder verknüpft
Zu jedem Kunden, identifiziert durch dessen ID, kann es mehrere Bestellungen geben. Das Feld KundeID der Tabelle bezieht sich auf die ID des Kunden. Damit ist die Verbindung hergestellt. Ähnlich verhält es sich mit den Tabellen zu Bestelldetails und Artikeln. Hier stellt jeweils die ID den Primärschlüssel dar, auf den sich die Datensätze einer Detailtabelle über einen Schlüssel xxxID verweisen. Die Bestelldetails machen das gleich zweimal.
Die Indizierung der beteiligten Schlüsselfelder ist immer dann zwingend, wenn Sie eine automatische Lösch- und Aktualisierungsweitergabe erreichen möchten. Access erlaubt die Einstellung dieser Optionen für eine Beziehung nur dann, wenn bereits Indizes auf die Felder gesetzt wurden. Das Löschen eines Kunden zieht dann das Löschen auch aller seiner Bestellungen samt Bestelldetails nach sich.
Doch oft ist Lösch- oder Aktualisierungsweitergabe gar nicht erforderlich oder erwünscht. Auch dann wird aber zu einer Indizierung geraten, weil dies der Performance zugutekommt. Sollen etwa die Bestellungen eines Kunden mit der ID 79 gefunden werden, so muss die Datenbank-Engine alle Datensätze der Tabelle tblBestellungen durchlaufen und die Werte von KundeID mit dieser Zahl vergleichen.
Bei Millionen von Bestelldatensätzen dauert dies recht lange. Ist das Feld KundeID aber indiziert, so zieht Access dessen Index zurate. Dieser erlaubt eine viel schnellere Suche nach dem Wert 79.
Soll gar zu einem Kunden ermittelt werden, welche Artikel er bereits bestellte, so ist die Tabelle tblBestelldetails und deren Feld ArtikelID zu durchsuchen. Da dies nur über den Umweg der Zwischentabelle tblBestellungen geschehen kann, sind nun schon zwei Tabellen verschachtelt komplett zu durchsuchen. Das potenziert die Suchdauer.
Der zweite Anwendungsfall für einen Index ist die unmittelbare Suche nach einem Feldinhalt. Möchten Sie etwa einen Kunden über dessen Namen finden, so muss Access wieder alle Datensätze scannen, um den oder die gewünschten zu erkennen. Sind die Namensfelder mit Indizes versehen, so verwendet die Engine diese zur Suche, was abermals schneller abläuft.
Soweit ist dies alles wahrscheinlich kein Fremdland für Sie!
Was ist ein Index
Nehmen wir an, Sie hätten ein E-Book, wie das vorliegende, in dem Sie ein bestimmtes Thema finden möchten. Sie könnten nun eine Volltextsuche anstoßen, um nach einem Begriff zu suchen, und das dauert einige Zeit. Einfacher ist es da, sich eines Index im hinteren Teil des Buchs zu bedienen. Dort stehen zu jedem Begriff mehrere Seitenzahlen, über die Sie wahrscheinlich schneller zum Thema gelangen.
Ähnlich verhält es sich mit den Indizes einer Datenbank. Mache System weisen tatsächlich auch physisch einen Index auf. Zu einer DBase-Datenbank finden Sie etwa in der Regel neben der eigentlichen Datenbank (dbf) auch eine Datei mit der Endung idx, die lediglich die Indizes zu den Tabellen enthält. Intern speichert auch die Access Database Engine die Indizes in gesonderten Speicherbereichen, nur dass dies in der Oberfläche von Access nicht offenkundig ist. Indizieren Sie ein Tabellenfeld, so zeigt sich dies ja lediglich in der Entwurfsansicht am Eigenschaftenfeld Indiziert oder im Indizes-Dialog (Ribbon Entwurf | Indizes), wie in Bild 2. Intern hat Access aber Indextabellen angelegt.
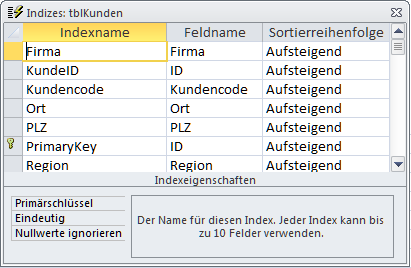
Bild 2: Der Indizes-Dialog zur Tabelle tblKunden im Entwurf
Um zur Analogie eines Buches zurückzukehren: Suchen Sie etwa nach Löschweitergabe, so suchen Sie erstens im Inhaltsverzeichnis nach der ersten Seite des Index. Dort finden Sie die Begriffe alphanumerisch sortiert vor. Sie blättern zur Seite mit dem L als Überschrift und finden in der Liste den Begriff Löschweitergabe mit drei angefügten Seitenzahlen. Sie inspizieren diese Seiten nacheinander, um die gewünschten Informationen zu erhalten. So ähnlich arbeitet auch ein Index unter Access.
Allerdings sind diese internen Indextabellen wesentlich komplexer und hochoptimiert, damit sich die Zahl der Sprünge zu Einträgen und Untereinträgen so gering hält, wie möglich. Die hier verwendeten Algorithmen sind eine Wissenschaft für sich und tragen Namen, wie B-Tree. Ein mögliches vereinfachtes Modell bei aufsteigender Sortierung für einen Index:
Unser exklusives Angebot für Dich!
(Das Abo ist jederzeit monatlich kündbar)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Oder hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →